

")

Zardoz
6 mois
Des avis sur les cartes PNY ?
 https://www.ldlc.pro/fiche/PB00710729.html
https://www.ldlc.pro/fiche/PB00710729.html
C'est moins cher qu''une 5090.
C'est moins cher qu''une 5090.
Je pense que si l'objectif n'est que de faire de l'inférence avec ollama, la radeon rx 7900 XTX est beaucoup moins chère et possède la même quantité de VRAM :  https://www.amazon.fr/-/e[...]X-79XMERCB9/dp/B0BNLSW23M
https://www.amazon.fr/-/e[...]X-79XMERCB9/dp/B0BNLSW23M
Le soucis avec cette carte, c'est que ce n'est pas NVIDIA donc elle ne bénéficie pas de l'écosystème CUDA assez pratique en IA
Mais si c'est juste pour utiliser ollama, ça devrait être compatible.
https://www.amazon.fr/-/e[...]X-79XMERCB9/dp/B0BNLSW23MLe soucis avec cette carte, c'est que ce n'est pas NVIDIA donc elle ne bénéficie pas de l'écosystème CUDA assez pratique en IA
Mais si c'est juste pour utiliser ollama, ça devrait être compatible.
il y a 6 mois
Sponsorisé
Connectez-vous pour masquer les pubsJe pense que si l'objectif n'est que de faire de l'inférence avec ollama, la radeon rx 7900 XTX est beaucoup moins chère et possède la même quantité de VRAM : https://www.amazon.fr/-/e[...]X-79XMERCB9/dp/B0BNLSW23M
Le soucis avec cette carte, c'est que ce n'est pas NVIDIA donc elle ne bénéficie pas de l'écosystème CUDA assez pratique en IA
Mais si c'est juste pour utiliser ollama, ça devrait être compatible.
https://www.amazon.fr/-/e[...]X-79XMERCB9/dp/B0BNLSW23MLe soucis avec cette carte, c'est que ce n'est pas NVIDIA donc elle ne bénéficie pas de l'écosystème CUDA assez pratique en IA
Mais si c'est juste pour utiliser ollama, ça devrait être compatible.
Effectivement, c'est un beau rapport VRAM/prix.
Mais comme tu le remarques, le support CUDA+Debian est terra incognita pour moi, alors qu'avec NVIDIA ça tourne.
Mais comme tu le remarques, le support CUDA+Debian est terra incognita pour moi, alors qu'avec NVIDIA ça tourne.
Certifié tous gaz.
il y a 6 mois
Effectivement, c'est un beau rapport VRAM/prix.
Mais comme tu le remarques, le support CUDA+Debian est terra incognita pour moi, alors qu'avec NVIDIA ça tourne.
Mais comme tu le remarques, le support CUDA+Debian est terra incognita pour moi, alors qu'avec NVIDIA ça tourne.
Justement CUDA c'est NVIDIA
Avec ce GPU AMD, il te faudra ROCm
Avec ce GPU AMD, il te faudra ROCm
il y a 6 mois
Justement CUDA c'est NVIDIA
Avec ce GPU AMD, il te faudra ROCm
Avec ce GPU AMD, il te faudra ROCm
Si tu préfères, j'en ai chié pas mal pour monter un setup qui marche. C'est pas tant ollama, qui roule comme un horloge, que la génération d'image où tu as un tas de dépendances sur les versions (telle version minimale des drivers graphiques pour supporter tes cartes MAIS PAS supérieure à ce que ton OS/noyau supporte, telle version précise de Python).
Changer une pièce, c'est pratiquement la certitude de tomber dans un trou noir comme je viens de l'apprendre à mes dépens en faisant un bête apt upgrade (24 heures de down, et j'ai été chanceux).
Donc changer mon fusil d'épaule pour passer de NVIDIA à AMD, c'est une opération à risque. Pour le moment, j'ai deux 4060 Ti, total 32G qui m'ont coûté 600 balles pièce. C'est confortable mais on veut toujours un peu plus. Je regarde ce qui se pointe sur le marché pour aller au-delà sans me ruiner, ou en me ruinant modérément.
Changer une pièce, c'est pratiquement la certitude de tomber dans un trou noir comme je viens de l'apprendre à mes dépens en faisant un bête apt upgrade (24 heures de down, et j'ai été chanceux).
Donc changer mon fusil d'épaule pour passer de NVIDIA à AMD, c'est une opération à risque. Pour le moment, j'ai deux 4060 Ti, total 32G qui m'ont coûté 600 balles pièce. C'est confortable mais on veut toujours un peu plus. Je regarde ce qui se pointe sur le marché pour aller au-delà sans me ruiner, ou en me ruinant modérément.
Certifié tous gaz.
il y a 6 mois
Si tu préfères, j'en ai chié pas mal pour monter un setup qui marche. C'est pas tant ollama, qui roule comme un horloge, que la génération d'image où tu as un tas de dépendances sur les versions (telle version minimale des drivers graphiques pour supporter tes cartes MAIS PAS supérieure à ce que ton OS/noyau supporte, telle version précise de Python).
Changer une pièce, c'est pratiquement la certitude de tomber dans un trou noir comme je viens de l'apprendre à mes dépens en faisant un bête apt upgrade (24 heures de down, et j'ai été chanceux).
Donc changer mon fusil d'épaule pour passer de NVIDIA à AMD, c'est une opération à risque. Pour le moment, j'ai deux 4060 Ti, total 32G qui m'ont coûté 600 balles pièce. C'est confortable mais on veut toujours un peu plus. Je regarde ce qui se pointe sur le marché pour aller au-delà sans me ruiner, ou en me ruinant modérément.
Changer une pièce, c'est pratiquement la certitude de tomber dans un trou noir comme je viens de l'apprendre à mes dépens en faisant un bête apt upgrade (24 heures de down, et j'ai été chanceux).
Donc changer mon fusil d'épaule pour passer de NVIDIA à AMD, c'est une opération à risque. Pour le moment, j'ai deux 4060 Ti, total 32G qui m'ont coûté 600 balles pièce. C'est confortable mais on veut toujours un peu plus. Je regarde ce qui se pointe sur le marché pour aller au-delà sans me ruiner, ou en me ruinant modérément.
T'as raison si j'étais toi je ne tenterais pas non plus.
Tu dépends de l'IA pour ton travail ou tu fais ça dans ton temps libre ?
Tu dépends de l'IA pour ton travail ou tu fais ça dans ton temps libre ?
il y a 6 mois




Vous recommandez quoi comme LLM local pour faire de l'extraction de données? J'utilise Gemini, ça fait le taf proprement mais j'aimerais avoir une solution locale. J'explique mon usage: je lui donne un prompt assez gros avec la structure json attendue, puis je lui envoie des fichiers png (des tableaux de données) et txt, son rôle est d'extraire les infos de ces fichiers (les lires donc) et les mettre sous forme d'un json.
C'est tout ce que je demanderai à mon LLM local, je suppose qu'en 2k26 ça doit bien exister

C'est tout ce que je demanderai à mon LLM local, je suppose qu'en 2k26 ça doit bien exister
A chaque problème sa solution

il y a 6 mois
SeiferGamer57
6 mois
Vous recommandez quoi comme LLM local pour faire de l'extraction de données? J'utilise Gemini, ça fait le taf proprement mais j'aimerais avoir une solution locale. J'explique mon usage: je lui donne un prompt assez gros avec la structure json attendue, puis je lui envoie des fichiers png (des tableaux de données) et txt, son rôle est d'extraire les infos de ces fichiers (les lires donc) et les mettre sous forme d'un json.
C'est tout ce que je demanderai à mon LLM local, je suppose qu'en 2k26 ça doit bien exister
C'est tout ce que je demanderai à mon LLM local, je suppose qu'en 2k26 ça doit bien exister
Je pense que ce que tu veux faire doit être fait par étapes. D'abord extraire les données puis les mettre en forme (avec un autre modèle)
Pour détecter le texte à partir d'une image il faut que tu utilises ce qu'on appelle un OCR.
Après pour mettre tes données en forme tu peux utiliser n'importe-quel LLM généraliste que tu devrais fine-tuner pour ton cas d'usage.
Il n'y a pas de solution simple prête à être utilisée pour ton cas d'usage.
Pour détecter le texte à partir d'une image il faut que tu utilises ce qu'on appelle un OCR.
Après pour mettre tes données en forme tu peux utiliser n'importe-quel LLM généraliste que tu devrais fine-tuner pour ton cas d'usage.
Il n'y a pas de solution simple prête à être utilisée pour ton cas d'usage.
il y a 6 mois
OK, merci pour ta réponse, je vais continuer avec Gemini alors

A chaque problème sa solution
il y a 6 mois
SeiferGamer57
6 mois
OK, merci pour ta réponse, je vais continuer avec Gemini alors
En vrai je viens de regarder et qwen3vl semble pouvoir faire l'affaire. Je ne m'y connais pas vraiment en vrai je parle sans savoir.
Tu pourrais me filer un exemple d'image qui ressemble à ce que tu veux exploiter ? J'aimerais tester ça
Tu pourrais me filer un exemple d'image qui ressemble à ce que tu veux exploiter ? J'aimerais tester ça
il y a 6 mois
@SeiferGamer57 je viens de tester qwen3-vl:32b et je pense qu'il est capable de faire exactement ce dont tu as besoin.
il y a 6 mois
Sponsorisé
Connectez-vous pour masquer les pubsL'IA opensource pose un problème de sécurité.
Une étude se SentinelLABS a identifié 175,108 services ollama exposés publiquement dans 130 pays différents. Pour aggraver le problème, beaucoup de ces instances ont des API d'outils ouverts, des capacités de vision et des templates de prompt non censuré manquant de barrières de sécurité.
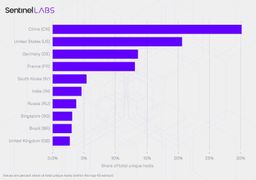
Ces systèmes requièrent une approche différente de la gouvernance : Contractuelle pour le déploiement en cloud ; Par des mécanismes d’assainissement (sanitation mechanisms) pour les réseaux résidentiels ou de tels contrats n'existent pas.
 https://www.sentinelone.c[...]yond-platform-guardrails/
https://www.sentinelone.c[...]yond-platform-guardrails/
Vous la sentez venir ?
Une étude se SentinelLABS a identifié 175,108 services ollama exposés publiquement dans 130 pays différents. Pour aggraver le problème, beaucoup de ces instances ont des API d'outils ouverts, des capacités de vision et des templates de prompt non censuré manquant de barrières de sécurité.
Ces systèmes requièrent une approche différente de la gouvernance : Contractuelle pour le déploiement en cloud ; Par des mécanismes d’assainissement (sanitation mechanisms) pour les réseaux résidentiels ou de tels contrats n'existent pas.
Vous la sentez venir ?
Certifié tous gaz.
il y a 6 mois
Ammortel
5 mois
J'ai testé et ça ne m'a pas l'air prêt à l'utilisation professionnelle
Par contre ollama a très bien évolué depuis l'année dernière j'ai l'impression
Par contre ollama a très bien évolué depuis l'année dernière j'ai l'impression
il y a 5 mois
J'ai testé et ça ne m'a pas l'air prêt à l'utilisation professionnelle
Par contre ollama a très bien évolué depuis l'année dernière j'ai l'impression
Par contre ollama a très bien évolué depuis l'année dernière j'ai l'impression
il y a 5 mois
L'image arrive sur ollama
 https://ollama.com/blog/image-generation
https://ollama.com/blog/image-generation
j'essayais justement d'en faire avec un script python et j'avais un bug de la carte graphique. Je me demande si ça fonctionnera avec ollama
il y a 5 mois
j'essayais justement d'en faire avec un script python et j'avais un bug de la carte graphique. Je me demande si ça fonctionnera avec ollama
Pour le moment c'est Mac only, mais ça n tardera pas à débarquer pour les autres.
Sinon pour les images, tu as pas mal de choix d'UI : ComfyUI, Automatic1111 pour ne cite que les précurseurs. En plus de l'UI, ils installent un REST API que ton script peut appeler sans se soucier de charger le modèle. Il faut cependant installer les drivers graphiques à la main.
Sinon pour les images, tu as pas mal de choix d'UI : ComfyUI, Automatic1111 pour ne cite que les précurseurs. En plus de l'UI, ils installent un REST API que ton script peut appeler sans se soucier de charger le modèle. Il faut cependant installer les drivers graphiques à la main.
Certifié tous gaz.
il y a 5 mois



Quelqu'un a utilisé qwen code next 80b ? Je trouves qu'il a tendance à changer le code fonctionnel à chaque fois et à changer des choses qui n'étaient pas nécessaire, à chaque changement demandé, on dirait qu'il regénère quelque chose de nouveau et introduit des nouveaux bugs.
Quelqu'un trouve qui a le même problème ?
Quelqu'un trouve qui a le même problème ?
Je vous aime les kheys, prenez soins de vous
il y a 5 mois
VisualStudio
5 mois
Quelqu'un a utilisé qwen code next 80b ? Je trouves qu'il a tendance à changer le code fonctionnel à chaque fois et à changer des choses qui n'étaient pas nécessaire, à chaque changement demandé, on dirait qu'il regénère quelque chose de nouveau et introduit des nouveaux bugs.
Quelqu'un trouve qui a le même problème ?
Quelqu'un trouve qui a le même problème ?
Peut-être que tu ne lui donnes pas assez de contexte ?
/show info
sur ollama pour voir le contexte. Par défaut c'est 262144 pour le coder de ce que je vois.
/show info
sur ollama pour voir le contexte. Par défaut c'est 262144 pour le coder de ce que je vois.
il y a 5 mois
VisualStudio
5 mois
Quelqu'un a utilisé qwen code next 80b ? Je trouves qu'il a tendance à changer le code fonctionnel à chaque fois et à changer des choses qui n'étaient pas nécessaire, à chaque changement demandé, on dirait qu'il regénère quelque chose de nouveau et introduit des nouveaux bugs.
Quelqu'un trouve qui a le même problème ?
Quelqu'un trouve qui a le même problème ?
Sinon c'est sûrement normal... Ce n'est pas le même niveau que chatGPT ou claude code.
il y a 5 mois



VisualStudio
5 mois
Quelqu'un a utilisé qwen code next 80b ? Je trouves qu'il a tendance à changer le code fonctionnel à chaque fois et à changer des choses qui n'étaient pas nécessaire, à chaque changement demandé, on dirait qu'il regénère quelque chose de nouveau et introduit des nouveaux bugs.
Quelqu'un trouve qui a le même problème ?
Quelqu'un trouve qui a le même problème ?
Toutes les IA ont le même pb, en texte ou en image :
- Elles ont tendance à retoucher ou modifier des choses qui marchent de manière "involontaire".
Tu as le même pb sur les IA qui font du code, en ligne : Elles modifient des fois des variables n'ayant rien à voir.
La meilleur solution reste la relecture humaine et de merger uniquement ce qui avait besoin d'être corrigé.

- Elles ont tendance à retoucher ou modifier des choses qui marchent de manière "involontaire".
Tu as le même pb sur les IA qui font du code, en ligne : Elles modifient des fois des variables n'ayant rien à voir.
La meilleur solution reste la relecture humaine et de merger uniquement ce qui avait besoin d'être corrigé.
Mon propos est imaginaire et fictif, il n'implique donc aucun fait ou élément réel et toute ressemblance serait fortuite
il y a 5 mois

En ligne
135
Sur ce sujet0