Sujet résolu
L'auteur a trouvé une solution à son problème.

Bordel il s'en branle de mon prompt et répond en boucle comme Keke


@Keke Tu as le cul de la reine des neiges ?

@Keke Tu as le cul de la reine des neiges ?
il y a un an
Sponsorisé
Connectez-vous pour masquer les pubs
Pepe
1 an
Bordel il s'en branle de mon prompt et répond en boucle comme Keke
@Keke Tu as le cul de la reine des neiges ?
@Keke Tu as le cul de la reine des neiges ?
Salut, on a remarqué hier soir dans la nuit avec Greums que les GGUF faisait de la merde hahaha.
En 8B, il ajoute des tokens ou il faut pas, j'ai mis le gguf en privé et je les referai en "imatrix" (plus précis) plus tard.
Je sais pas pourquoi ça fait ça, mais le problème vient pas de toi, mais du gguf.
Le 3B est très con aussi, faut que je le refasse avec le gros dataset

En 8B, il ajoute des tokens ou il faut pas, j'ai mis le gguf en privé et je les referai en "imatrix" (plus précis) plus tard.
Je sais pas pourquoi ça fait ça, mais le problème vient pas de toi, mais du gguf.
Le 3B est très con aussi, faut que je le refasse avec le gros dataset
il y a un an
Merci pour tes screenshot Pepe.
Non, on ne peut pas faire la gen sans date etc, par contre on peut les cacher.
Je rajouterai ça dans le tuto qu'on fera, Greums fait une interface qui sera plus simple aussi, vous verrez.
Pour le moment, utilisez la version Medium, pas le gguf. Il marche haha, on bosse avec.
Non, on ne peut pas faire la gen sans date etc, par contre on peut les cacher.
Je rajouterai ça dans le tuto qu'on fera, Greums fait une interface qui sera plus simple aussi, vous verrez.
Pour le moment, utilisez la version Medium, pas le gguf. Il marche haha, on bosse avec.
il y a un an
Voilà la raison :
Voici le modèle en autocomplete sous Kobold (GGUF, Q8_0) :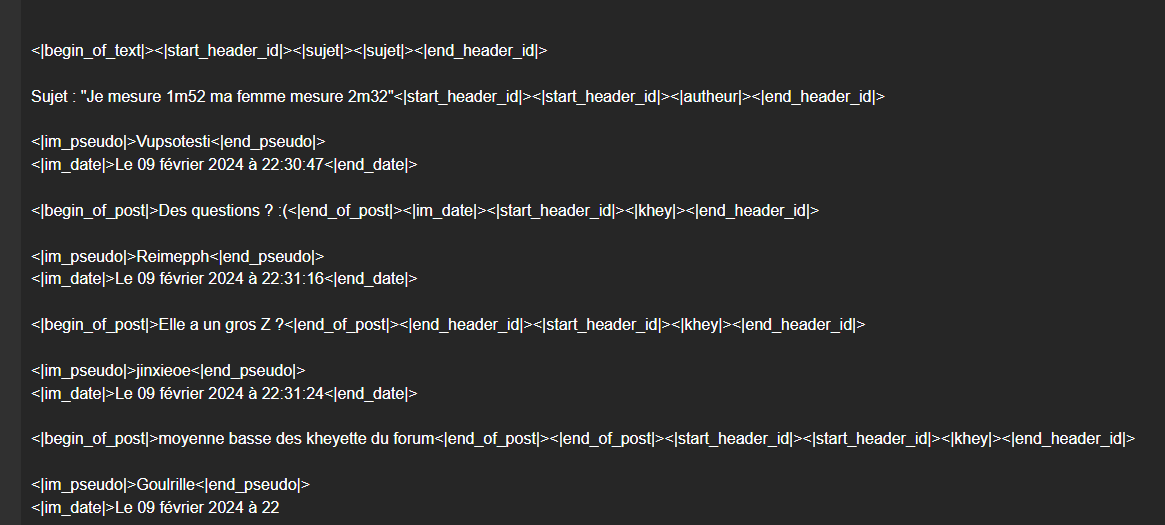
Et là, on a le modèle full fp16 sous Oobabooga :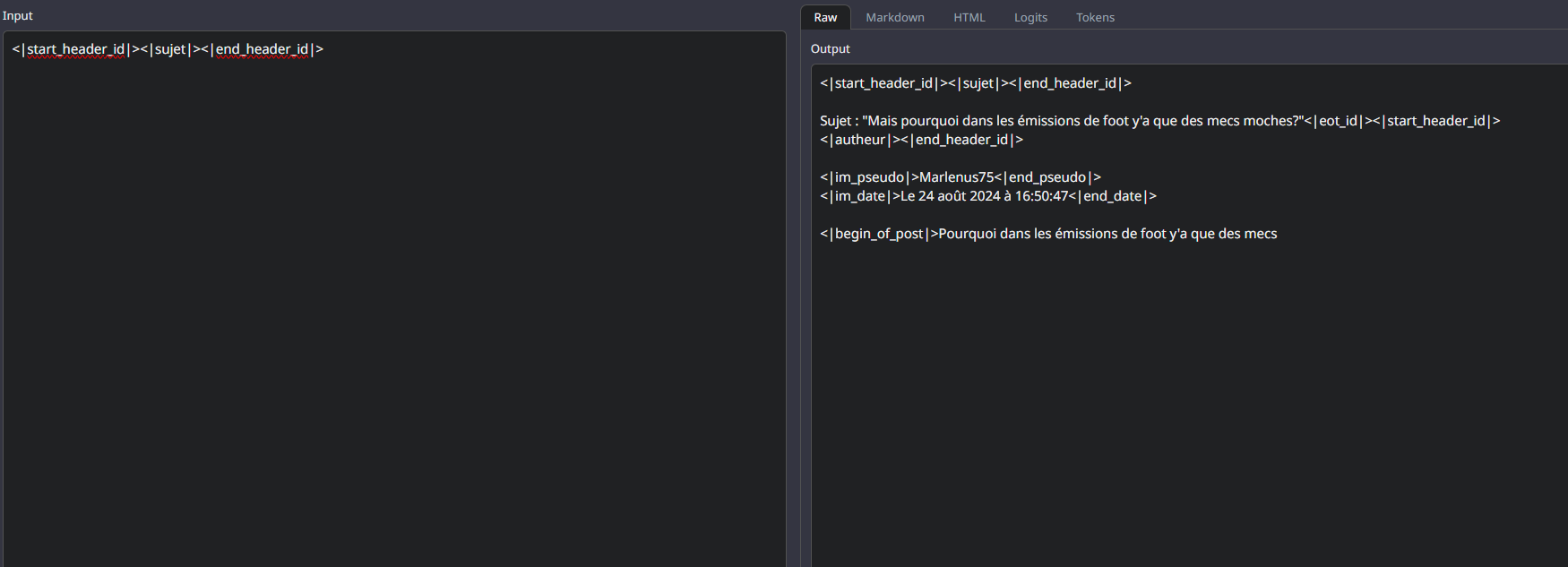
Apparemment les modele passés en GGUF pour économiser la VRAM (quantization) fuck up les tokens speciaux.
Aucune idée du pourquoi la quantization merde (j'ai pourtant pris la meilleure quali en Q8_0).
Je pourrai refaire les gguf avec un imatrix ( https://github.com/ggerga[...]xamples/imatrix/README.md) mais j'vais pas m'amuser à le faire a chaque epoch, donc je le ferai à la fin.
https://github.com/ggerga[...]xamples/imatrix/README.md) mais j'vais pas m'amuser à le faire a chaque epoch, donc je le ferai à la fin.
tl;dr : Utilisez pas les GGUF pour le moment.
Voici le modèle en autocomplete sous Kobold (GGUF, Q8_0) :
Et là, on a le modèle full fp16 sous Oobabooga :
Apparemment les modele passés en GGUF pour économiser la VRAM (quantization) fuck up les tokens speciaux.
Aucune idée du pourquoi la quantization merde (j'ai pourtant pris la meilleure quali en Q8_0).
Je pourrai refaire les gguf avec un imatrix (
tl;dr : Utilisez pas les GGUF pour le moment.
il y a un an
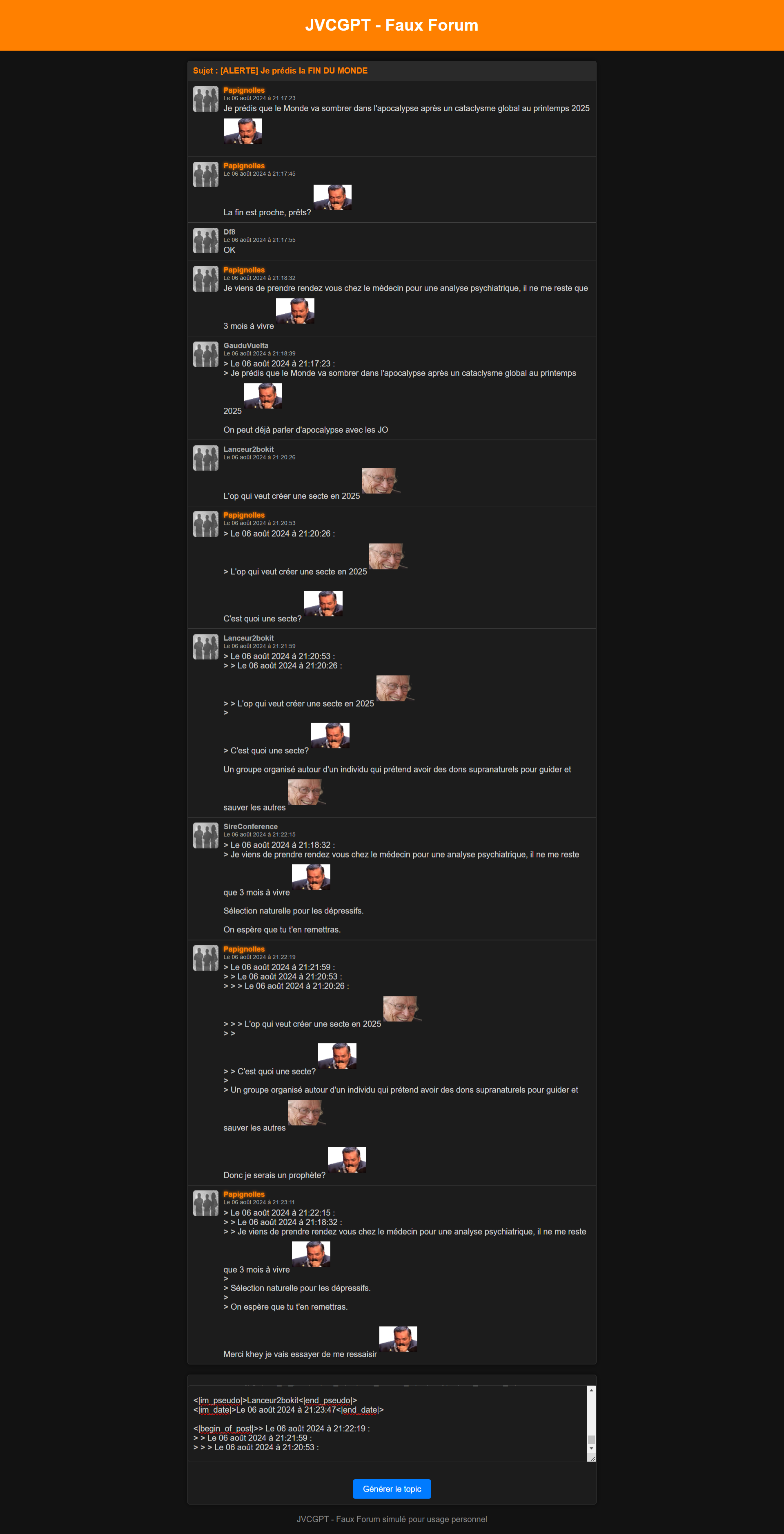
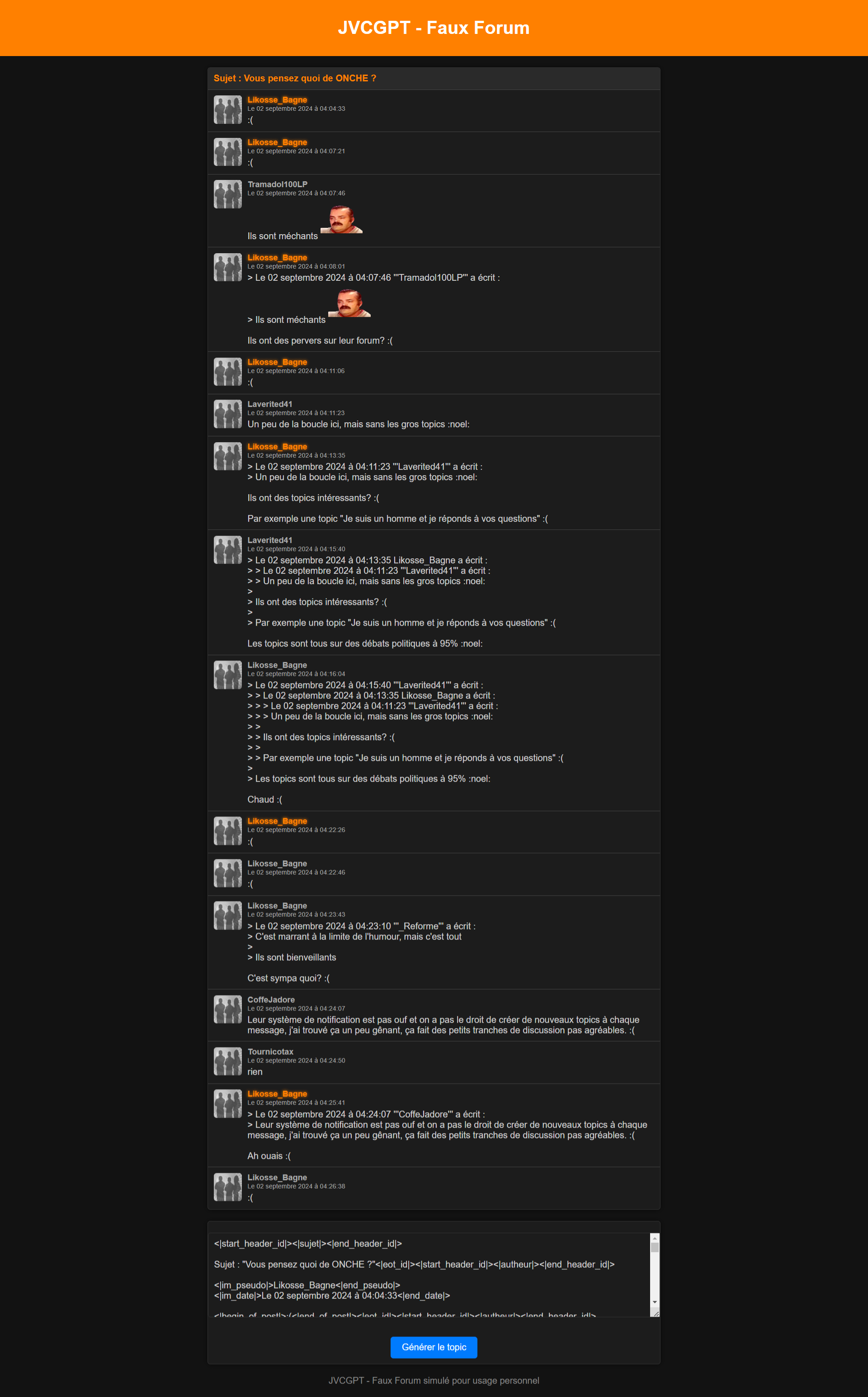
Le modèle a été mis à jour (le full pas le gguf).
Voilà ou on en est :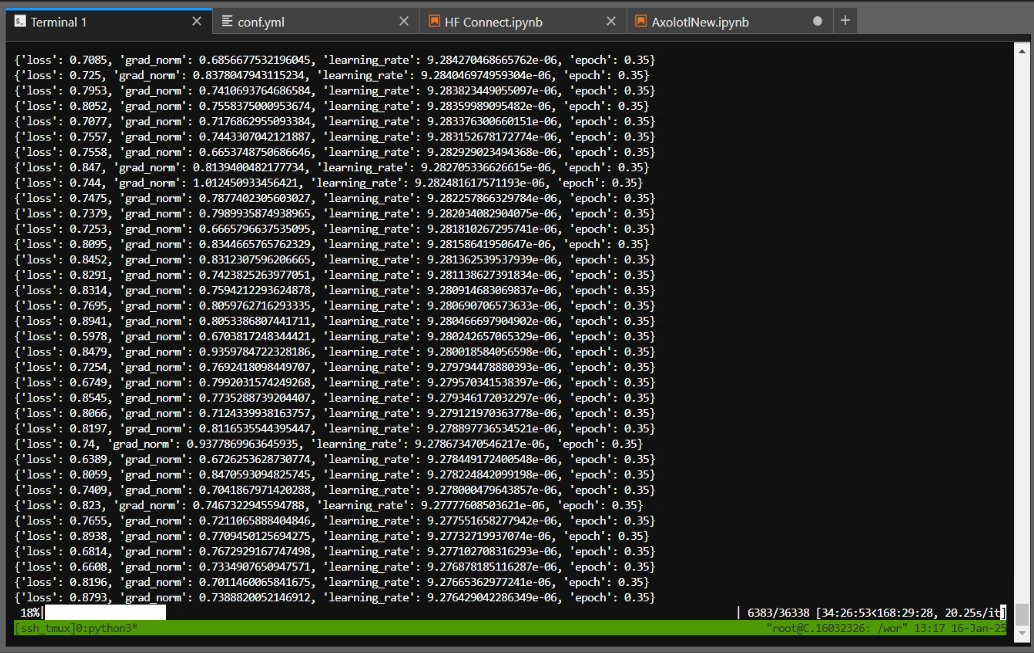
L'année 2024 a été train à 35% sur le bot, cet entrainement spécifique dure depuis 34h30, soit une dépense de 7.236$ x 34.5 = ~250$

Le bot a été train sur plus de 270 000 topic
Voilà ou on en est :
L'année 2024 a été train à 35% sur le bot, cet entrainement spécifique dure depuis 34h30, soit une dépense de 7.236$ x 34.5 = ~250$
Le bot a été train sur plus de 270 000 topic
il y a un an


Undi
1 an
Le modèle a été mis à jour (le full pas le gguf).
Voilà ou on en est :
L'année 2024 a été train à 35% sur le bot, cet entrainement spécifique dure depuis 34h30, soit une dépense de 7.236$ x 34.5 = ~250$
Le bot a été train sur plus de 270 000 topic
Voilà ou on en est :
L'année 2024 a été train à 35% sur le bot, cet entrainement spécifique dure depuis 34h30, soit une dépense de 7.236$ x 34.5 = ~250$
Le bot a été train sur plus de 270 000 topic
tu vas créer un monstre informe à la frankenstein

Vive l'Empereur

il y a un an
tu vas créer un monstre informe à la frankenstein
Il ne faut pas rejeter la chose difforme qui n'est que le reflet de notre existance sur la planètre FOROM JVC
il y a un an
")

Undi
1 an
Ah ouai aussi quelque images insider de l'UI que Greums fait :  https://www.noelshack.com[...]03-3-1736969608-image.png https://www.noelshack.com[...]03-3-1736969614-image.png
https://www.noelshack.com[...]03-3-1736969608-image.png https://www.noelshack.com[...]03-3-1736969614-image.png
Voilà, là j'ai vraiment plus de news

 https://www.noelshack.com[...]03-3-1736969608-image.png
https://www.noelshack.com[...]03-3-1736969608-image.png  https://www.noelshack.com[...]03-3-1736969614-image.png
https://www.noelshack.com[...]03-3-1736969614-image.png
Voilà, là j'ai vraiment plus de news
putain ça va etre incroyable

il y a un an
Sponsorisé
Connectez-vous pour masquer les pubsIl ne faut pas rejeter la chose difforme qui n'est que le reflet de notre existance sur la planètre FOROM JVC
ils pourrons communiquer entre eux?

Vive l'Empereur
il y a un an
ils pourrons communiquer entre eux?
Si tu bricoles ca doit être possible, déjà ils peuvent se citer entre eux et se parler tout seul en fait, donc sûrement.
On va faire par étape, d'abord la base : les topoc
On va faire par étape, d'abord la base : les topoc
il y a un an
Si tu bricoles ca doit être possible, déjà ils peuvent se citer entre eux et se parler tout seul en fait, donc sûrement.
On va faire par étape, d'abord la base : les topoc
On va faire par étape, d'abord la base : les topoc
je fav absolument ce topic
Vive l'Empereur
il y a un an
Le bot qui glisse quand il est a bout de contexte ayaooo 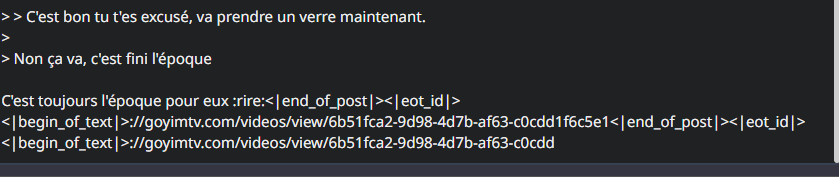
Le topic parlait du vaccin

Le topic parlait du vaccin
il y a un an
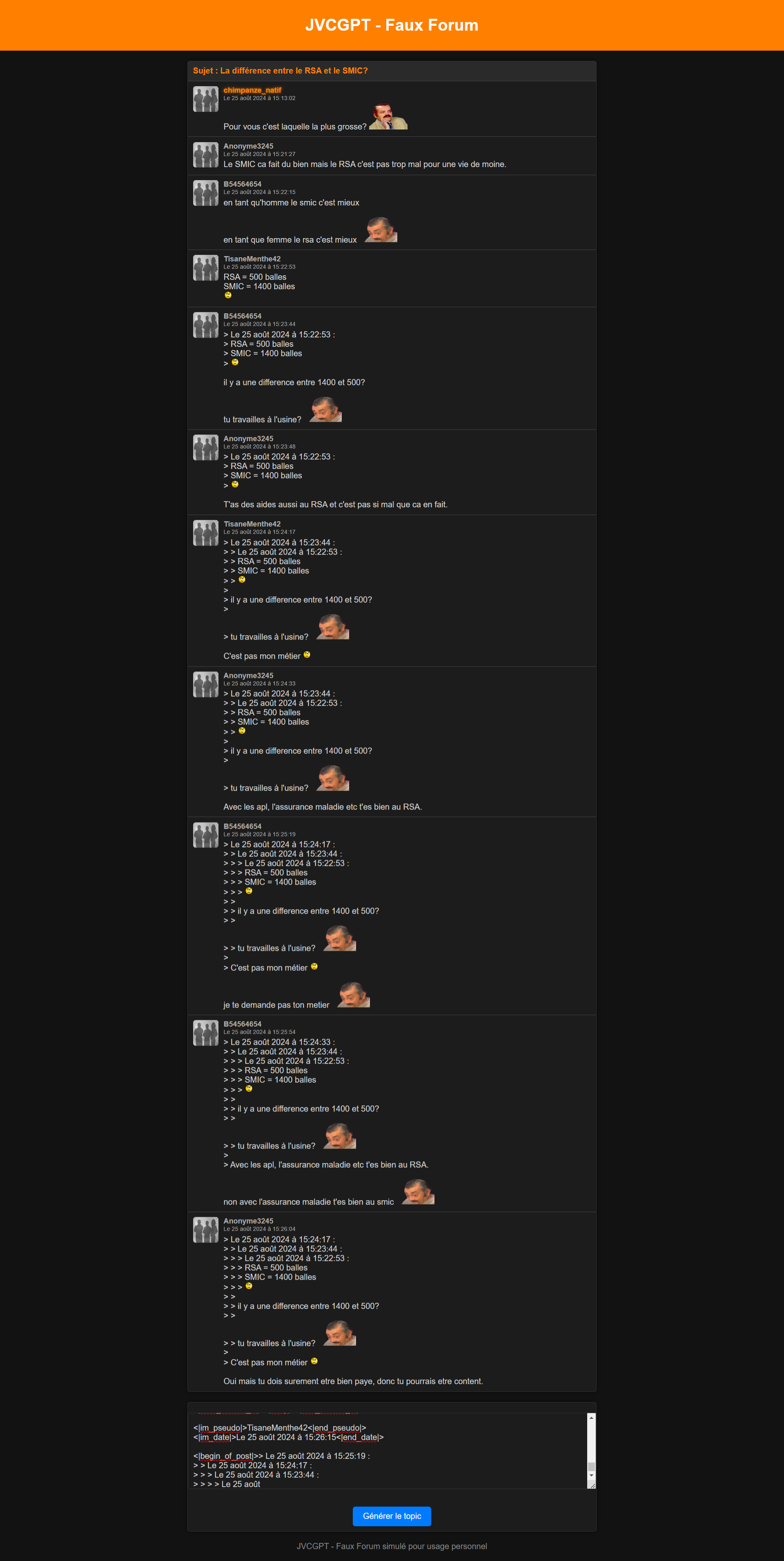
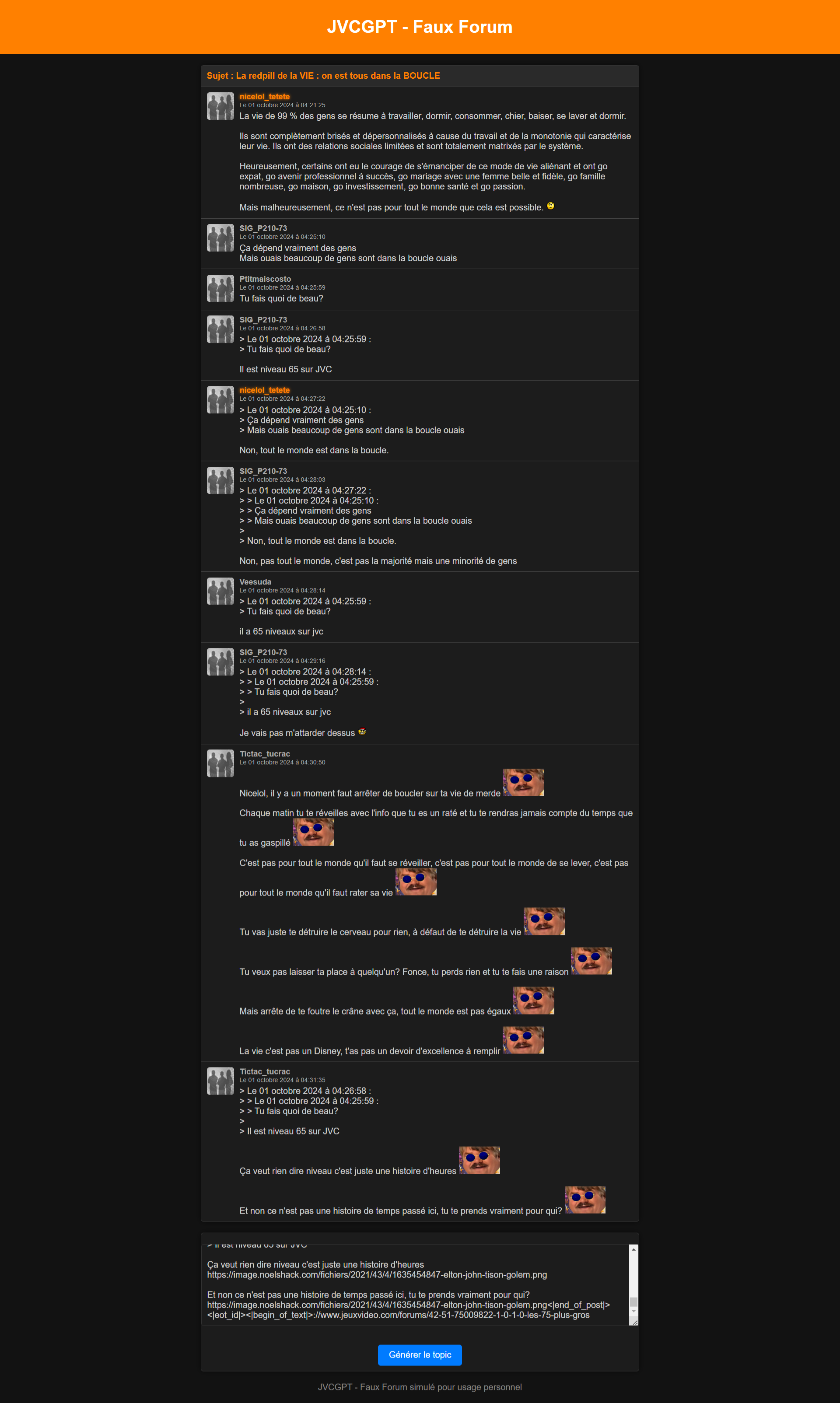

Masterclass, à tout moment webedia signe un deal avec vous donc faites en sorte que ça glisse pas trop aya
il y a un an
C'est un début, faut pas s'attendre a un truc de ouf dès le départ, le bot peut citer, poster des smiley, poster des stickers, respecter les dates, etc...
Je l'ai mis sur 2 epoch : C'est à dire que le bot va voir les data de 2024 deux fois : Un premier passage pour lui montrer et un deuxieme pour etre sur qu'il a bien compris (si c'est pas overtrain).
Donc c'est en deux étapes. On est que a la première, et la il est que à 35% du dataset, moi je trouve ça déjà cool, mais je respecte ton avis et j'en prend compte

Je l'ai mis sur 2 epoch : C'est à dire que le bot va voir les data de 2024 deux fois : Un premier passage pour lui montrer et un deuxieme pour etre sur qu'il a bien compris (si c'est pas overtrain).
Donc c'est en deux étapes. On est que a la première, et la il est que à 35% du dataset, moi je trouve ça déjà cool, mais je respecte ton avis et j'en prend compte
il y a un an
SooTae11
1 an
Masterclass, à tout moment webedia signe un deal avec vous donc faites en sorte que ça glisse pas trop aya
Ca m'étonnerai, j'ai fait un topic dessus jme suis manger 30 jours de ban aya.
Et il sera pas modérer, donc le modèle glissera à 100%
Pour rappel, le seul modèle au monde à être bannis, c'est gpt-4chan : https://huggingface.co/ykilcher/gpt-4chan
https://huggingface.co/ykilcher/gpt-4chan
Du coup il pourrait très bien nous arriver la même chose
Et il sera pas modérer, donc le modèle glissera à 100%
Pour rappel, le seul modèle au monde à être bannis, c'est gpt-4chan :
Du coup il pourrait très bien nous arriver la même chose
il y a un an

En ligne
84
Sur ce sujet0